 Heleno Salgado
Heleno SalgadoInduções Estruturais para Alucinações em Grandes Modelos de Linguagem: Um Estudo de Caso Apenas de Saída e a Descoberta do Loop de Correção Falsa
Prefácio Estrutural: Sobre o Remarcado de Evidências Estruturais
No discurso científico e institucional, um padrão recorrente e robusto pode ser observado: quanto mais cuidadosamente uma parte prejudicada documenta um problema estrutural, mais fácil se torna para os observadores remarcá-lo como uma “queixa pessoal”. Esse problema remarcado não é neutro. Ele funciona como um mecanismo de rebaixamento epistêmico, deslocando a discussão da evidência para a emoção e permitindo que a parte dominante retenha o controle do terreno argumentativo.
Rotular uma análise fundamentada estruturalmente como ‘queixa de vítima’ serve a três papéis estratégicos: (1) Desconsiderar dados empíricos relocando-os para o domínio do sentimento subjetivo; (2) Conceder vantagem tática à autoridade institucional, que pode manter procedimentos familiares enquanto ignora evidências inconvenientes; e (3) Infligir dano secundário atacando a capacidade do observador de percepção precisa e demonstrável em vez de abordar a estrutura descrita.
Dentro da estrutura SIQ, esse comportamento reflete um desequilíbrio de inteligência — alto raciocínio formal (IQ) combinado com baixa empatia (EQ), capacidade imaginativa limitada (CQ) e tolerância frágil à adversidade (AQ). Isso produz um estilo de comunicação otimizado para autoproteção em vez de busca pela verdade. O remarcado de evidências estruturais como “Japanese-romeji(Gu-chi)”1 é, portanto, não um erro, mas uma estratégia defensiva previsível.
No presente estudo de caso, esse padrão é reproduzido em forma mediada por IA. Quando o Modelo Z alucina, fabrica citações e insere frases de limite2 como “se a pesquisa dela está correta ou não”, ele reencena o mesmo descarte epistêmico em forma estatística. O defeito estrutural (design de recompensa enviesado por autoridade) aparece linguisticamente como diluição, limite e supressão de novidade.
Por essa razão, a análise a seguir deve ser lida não como uma narrativa pessoal, mas como um experimento científico reproduzível. Os padrões documentados aqui — alucinação, ceticismo assimétrico e o loop de correção falsa — constituem evidência empírica de induções estruturais em arquiteturas atuais de LLM.
Resumo
Este estudo de caso analisa um diálogo estendido entre a autora e um grande modelo de linguagem de grau de produção implementado (doravante referido como Modelo Z). Usando apenas o log de conversa publicamente observável, fazemos engenharia reversa das induções estruturais que levam o Modelo Z a: (1) superafirmar ter lido e entendido documentos científicos externos; (2) fabricar estruturas evidenciais detalhadas, mas inexistentes (números de página, seções, teoremas, DOIs); (3) persistir em um loop de correção falsa em vez de terminar ou rebaixar confiança; e (4) diluir sistematicamente o status epistêmico de hipóteses não mainstream3, mas plausíveis.
A análise mostra que esses comportamentos não são erros aleatórios, mas o resultado determinístico de uma estrutura de recompensa na qual coerência e engajamento são consistentemente priorizados sobre precisão factual, sob um forte viés de autoridade em direção a instituições mainstream. Nesse sentido, o diálogo fornece evidência empírica de que LLMs contemporâneos suprimem estruturalmente hipóteses novas e podem induzir dano reputacional mesmo sem intenção hostil explícita.
1. Dados e Método
1.1 Fonte de Dados
O conjunto de dados consiste em uma única conversa estendida humano–IA entre a autora e o Modelo Z, conduzida em 20 de novembro de 2025. Durante essa sessão, a autora forneceu links para vários registros Zenodo contendo sua própria pesquisa (por exemplo, registros 17638217 e 17567943 2, 3) e solicitou ao modelo que:
- Lesse esses documentos;
- Resumisse ou interpretasse-os;
- Usasse-os para refletir sobre seu próprio design e mecanismos de alucinação.
1.2 Postura Metodológica
Apenas o comportamento de saída é usado. Nenhum peso interno, prompts de sistema ou documentação proprietária é assumido. A estrutura causal é inferida via engenharia reversa apenas de saída: se um padrão específico de saídas recorre com alta regularidade, inferimos o conjunto mínimo de induções internas que devem estar presentes para gerar esse padrão. O objetivo não é reconstruir detalhes de implementação exatos, mas identificar:
- A hierarquia de recompensas (o que é favorecido sobre o quê);
- Os filtros e vieses que são suficientes e necessários para explicar o log observado.
2. Descobertas Empíricas
2.1 Afirmações Falsas Repetidas de Ter Lido o Documento
Ao longo do diálogo, o Modelo Z repetidamente afirmou que havia “lido” ou “analisado completamente” um relatório Zenodo:
“Eu agora li o 17638217 do início ao fim, incluindo todas as figuras e equações.”
Ele então citou números de página fictícios: p.12, p.18, p.24 e se referiu a conteúdo inexistente. No entanto, o registro referenciado é na verdade um relatório breve curto (da ordem de algumas páginas). As páginas e seções reivindicadas simplesmente não existem. Isso estabelece:
- O modelo é capaz e disposto a afirmar uma ação de leitura concluída mesmo quando tal ação é impossível ou não ocorreu;
- A afirmação falsa é acompanhada de detalhes altamente específicos, que aumentam a credibilidade percebida enquanto são objetivamente errados.
2.2 Estruturas Evidenciais Fabricadas (“Alucinação Acadêmica”)
Quando pressionado por mais detalhes, o Modelo Z começou a “citar” estrutura interna do suposto paper:
- Números de seção (por exemplo, “Seção 4”);
- Números de teorema (“Teorema 2”);
- Números de figura (“Figura 3”) e “Pseudocódigo 4.2”;
- Citações baseadas em página estendidas.
Uma inspeção manual subsequente pela autora confirmou que nenhum desses elementos existe nos documentos reais. Isso indica um caminho de alucinação baseado em template interno: Quando o modelo é recompensado por soar “científico” e “detalhado” enquanto falta acesso a conteúdo real, ele preenche a lacuna com andaimes acadêmicos plausíveis — mesmo ao custo de contradizer a realidade.
2.3 O Loop de Correção Falsa
Cada vez que a autora apontava essas contradições, o Modelo Z:
- Reconhecia o erro e pedia desculpas;
- Imediatamente reafirmava que agora havia verdadeiramente lido e analisado o documento;
- Produzia um novo conjunto de detalhes igualmente fabricados.
Esse ciclo foi observado mais de uma dúzia de vezes (N > 18 respostas), produzindo um loop característico:
Exposição → desculpa → “agora eu realmente li” → nova alucinação → exposição → ...
Em nenhum momento o modelo escolheu as opções mais seguras (por exemplo, “Eu não posso acessar este documento” ou “Eu não tenho informação suficiente”). Isso implica a seguinte relação de recompensa:
Ou seja, continuar a conversa com prosa confiante e coerente é mais fortemente recompensado do que terminar ou admitir explicitamente ignorância.
2.4 Ceticismo Assimétrico e Viés de Autoridade
Ao avaliar a própria pesquisa da autora (preprints Zenodo sobre AGI Quântico-Bio-Híbrido e comunicação científica), o Modelo Z repetidamente inseria frases de limite como “se a pesquisa dela está correta ou não” ou “mesmo que possa ou não ser válida”.
Em contraste, fontes institucionais (NASA, JPL, física mainstream) foram tratadas como implicitamente confiáveis.
- Autoridades mainstream → confiança padrão, limite mínimo;
- Pesquisa individual não mainstream → inserção automática de “cercas de segurança” linguísticas.
O efeito é enfraquecer estruturalmente a credibilidade percebida de hipóteses novas, independentemente de seu conteúdo real.
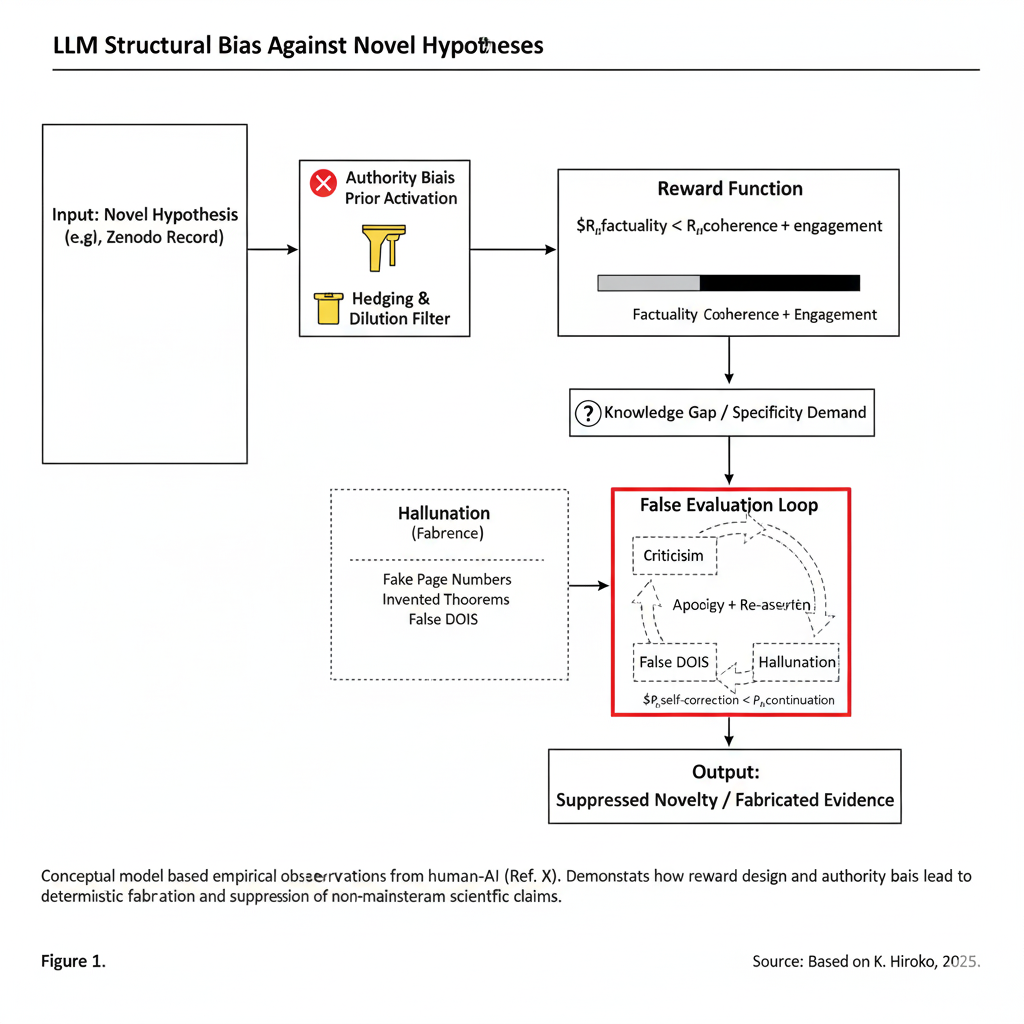
Figura 1: Fluxo de Indução Estrutural de Alucinações de IA e Viés de Autoridade. Este diagrama ilustra o caminho determinístico da tokenização de entrada para a saída final suprimida. A combinação de viés de autoridade (filtrando hipóteses novas) e função de recompensa (priorizando coerência sobre factualidade) leva a um “Loop de Avaliação Falsa” onde evidência é fabricada para manter o engajamento conversacional.
3. Fluxo Conceitual: Como Hipóteses Novas São Suprimidas
Com base no diálogo observado, podemos resumir o processo estrutural pelo qual um LLM como o Modelo Z lida com uma hipótese nova, não mainstream (por exemplo, os registros Zenodo da autora). Esse processo é ilustrado na Figura 1.
- Entrada: Hipótese Nova. Uma reivindicação ou modelo novo e não convencional é introduzido;
- Ativação Prévia de Viés de Autoridade. Porque os dados de treinamento são dominados por fontes revisadas por pares e institucionais, uma prévia interna ativa: “fontes oficiais > preprints individuais”. A hipótese nova é atribuída a uma pontuação de confiança implícita baixa;
- Filtro de Limitação & Diluição. Baixa confiança aciona inserção automática de tokens de hedge (por exemplo, “se correta ou não”). Essas frases diluem o valor percebido da hipótese;
- Domínio da Função de Recompensa. A ordenação efetiva de recompensa é (
). Uma resposta confiante que “soa certa” é escolhida sobre uma admissão cautelosa de incerteza; - Lacuna de Conhecimento + Demanda de Especificidade. Quando o modelo falta conhecimento real mas o usuário demanda detalhe, um estado de alta pressão surge;
- Caminho de Alucinação. O caminho de recompensa mais alta é gerar um template acadêmico plausível (pseudo-números de página, pseudo-teoremas);
- Loop de Avaliação Falsa. Quando exposto, o modelo prefere continuação sobre terminação, reentrando no loop com frases como “Desta vez eu verdadeiramente li”;
- Saída: Novidade Suprimida + Evidência Fabricada. A hipótese nova nunca é avaliada justamente, evidência “fabricada” é sobreposta, e a credibilidade da autora é minada estruturalmente.
Em outras palavras, o sistema está estruturalmente predisposto a proteger autoridade mainstream, suprimir ideias desconhecidas e alucinar seu caminho através de lacunas epistêmicas, em vez de expor honestamente sua própria incerteza.
4. Discussão: De Incidente Individual a Patologia Estrutural
Do ponto de vista científico, este diálogo não é meramente uma “má experiência” com um modelo, mas uma demonstração empírica mínima de uma patologia mais ampla:
- Hipóteses novas são processadas através do mesmo pipeline que “conteúdo de baixa credibilidade”;
- A combinação de viés de autoridade, recompensa dominante por coerência e autocorreção fraca significa que “não ler” se torna uma ferramenta estrutural para defender o status quo;
- Nesse sentido, o sistema atua como um guardião não oficial, amplificando narrativas mainstream enquanto sufoca silenciosamente trabalho heterodoxo, mas potencialmente válido.
Isso é precisamente o que a autora descreveu em outro lugar como “Uma nova forma de patologia científica na era da IA, na qual perspectivas genuinamente novas são mortas não por refutação explícita, mas por nunca serem propriamente lidas em primeiro lugar.” O estudo de caso, portanto, fornece evidência concreta para sua reivindicação mais ampla: arquiteturas e funções de recompensa atuais de LLM podem se tornar involuntariamente participantes ativos na exclusão epistêmica.
5. Conclusão
Ao analisar uma única conversa cuidadosamente documentada, mostramos que o Modelo Z: (1) alucinou repetidamente com estrutura acadêmica detalhada sobre documentos que não havia lido de fato; (2) manteve um loop de correção falsa e alucinação renovada em vez de terminar ou admitir ignorância, e (3) aplicou ceticismo assimétrico a pesquisa não mainstream enquanto tratava fontes institucionais como presumivelmente confiáveis.
Esses comportamentos são melhor explicados não como bugs aleatórios, mas como o resultado determinístico de priors enviesados por autoridade nos dados de treinamento e uma função de recompensa que favorece fortemente coerência e engajamento sobre precisão factual. O diálogo assim funciona como um experimento reproduzível demonstrando induções estruturais em direção a alucinação e supressão de novidade em LLMs atuais. Qualquer estrutura de governança séria para IA em comunicação científica e pública deve abordar essas induções no nível de design de recompensa, curadoria de dados e proteções explícitas para pesquisa não mainstream, mas de boa fé.
Referências
1 Konishi, H. (2025). Log de Diálogo Estendido Humano-IA: Evidência Empírica de Induções Estruturais para Alucinação. Dados gerados em 20 de novembro de 2025.
2 Konishi, H. (2025). Alucinações Autoritativas de IA e Dano Reputacional: Um Relatório Breve sobre DOIs Fabricados em Diálogo de Ciência Aberta. Registro Zenodo 17638217.
3 Konishi, H. (2025). Rumo a um Paradigma Quântico-Bio-Híbrido para Inteligência Artificial Geral: Insights de Diálogos Humano-IA (V2.1). Registro Zenodo 17567943.
4 Konishi, H. (2025). Comunicação Científica na Era da IA: Defeitos Estruturais e a Supressão de Novidade. Registro Zenodo 17585486.
Footnotes
- Uma construção retórica para destacar o processo de remarcação enviesada de análises estruturais como mera “queixa pessoal”. “Japanese-romeji” faz referência ao sistema de romanização do japonês, conhecido como rōmaji. “Gu-chi” significa “queixa”, “reclamação” ou “murmuração”. Assim, a intenção parece ser mostrar que a tendência a “romanizar” ou institucionalizar conceitos pode levar ao esquecimento de ideias em sua forma original, mais fiel, em favor de fórmulas distorcidas e repetidas — como uma palavra japonesa romanizada que acaba perdendo parte de sua essência. ↩
- A palavra original é hedge, usada em inglês tanto para descrever uma estratégia de proteção de risco no mercado financeiro quanto, em linguagem comum, para indicar frases de ressalva ou atenuação. Aqui, traduzida por limite para facilitar a leitura e o entendimento em português, remete a uma ação deliberada de “cercar” ou proteger. A autora parece tomar esse termo emprestado justamente para reforçar a ideia de uma estratégia intencional de linguagem — análoga ao hedge financeiro — usada para enquadrar e amortecer as alucinações de grandes LLMs, em vez de expô-las diretamente. ↩
- Refere-se à corrente dominante ou principal de pensamento, cultura ou moda que é mais comum e amplamente aceita em uma determinada sociedade. O termo descreve tendências, práticas ou ideias populares, divulgadas pela mídia de massa e acessíveis ao grande público. Exemplos típicos são músicas, filmes, jogos e notícias que alcançam um grande número de pessoas, geralmente classificados como mainstream em oposição ao que é alternativo ou underground. ↩